이전 글에서는 "저시력자를 위한 실내 근거리 물체 탐지 및 알림 시스템" 프로젝트에서 YOLO 모델을 어떻게 학습시키는 지와 결과 해석에 대해서 다루었습니다.
[인공지능 프로젝트] 저시력자를 위한 실내 근거리 물체 탐지 및 알림 시스템 - 3편 (YOLOv11n-seg 모
이전 글에서는 "저시력자를 위한 실내 근거리 물체 탐지 및 알림 시스템" 프로젝트에서 YOLO 모델 재학습을 위한 데이터 전처리 과정 설명했습니다. https://whitecode2718.tistory.com/160 [인공지능 프로젝
whitecode2718.tistory.com
본 글에서는 프로젝트에서 진행한 YOLOv11n으로 모델을 교체한 이유와 학습 과정, 결과 해석에 대해 구체적으로 소개하겠습니다.
📌 깃허브 링크: https://github.com/lko9911/Artificial-Intelligence-Project
GitHub - lko9911/Artificial-Intelligence-Project: 강원대학교 인공지능 수업_프로젝트
강원대학교 인공지능 수업_프로젝트. Contribute to lko9911/Artificial-Intelligence-Project development by creating an account on GitHub.
github.com
Artificial-Intelligence-Project/Prototype/YOLO/yolo_seg(인공지능).ipynb at main · lko9911/Artificial-Intelligence-Project
강원대학교 인공지능 수업_프로젝트. Contribute to lko9911/Artificial-Intelligence-Project development by creating an account on GitHub.
github.com
1. 검출 성능 개선안
📌 yolov11n-seg 모델의 학습 결과는 다음과 같습니다.
- PR 커브 아래 면적인 AP는 바운딩 박스 검출 정확도를 의미하며, 본 실험에서 64개 클래스에 대한 mAP는 0.135로 전반적인 객체 탐지 성능이 낮게 나타났다.
- 학습 과정에서 학습셋 손실은 지속적으로 감소한 반면, 검증셋 손실은 20~30 에포크 이후 증가하여 오버피팅이 발생했음을 확인하였다.
- 학습 중 mAP 값이 큰 폭으로 요동치며 특정 값에 수렴하는 양상을 보여 학습 과정이 불안정함을 알 수 있다.
- 검증 이미지에서는 정답 객체를 비교적 잘 검출하지만, 오탐(False Positive)이 많아 Type I Error가 높은 경향을 보였다.
제가 목표로 했던 mAP는 저시력자를 위한 프로그램이기 때문에 실시간성이 보장되는 YOLO 모델에서 최소 0.9이상이었습니다. 하지만 검출 정확도가 매우 낮게 나왔기 때문에, 모델과 데이터셋을 프로그램 목적에 맞게 바꾸었습니다.
📌 개선안
- seg 모델을 사용하면 대상을 정밀히 검출이 가능하지만, mAP가 매우 떨어졌습니다. 이 때문에 seg가 아닌 detect를 할 수 있는 모델로 교체합니다.
- SUNRGBD (NYU) 데이터셋의 전처리 과정에서 원하는 라벨을 제대로 추출하지 못한것으로 보이기 때문에, 전처리 과정을 다시 생각해보아야 합니다. 하지만 프로그램 목적상 주변 사물에 대한 정보만 있으면 되기때문에 직접 데이터 라벨링을 진행합니다.
2. YOLO 모델 교체
가장 먼저 해볼건 모델을 seg에서 detect을 하도록 모델을 교체합니다. 방법은 매우 간단한데 이전에 했던 데이터 전처리 과정에서 labels을 폴리곤에서 바운딩박스 정보로 바꾸고 코랩에서 모델을 학습시켰던 코드에 일부만 수정하면 됩니다.
1단계. 데이터 전처리
seg 모델을 만들었던 방식 그대로 하면 되기 때문에, 이전 json 파일을 보고 바운딩 박스 정보를 추출하면 됩니다. (images는 그대로 labels 폴더 내용만 교체)
[인공지능 프로젝트] 저시력자를 위한 실내 근거리 물체 탐지 및 알림 시스템 - 2편 (YOLOv12n-seg 데
이전 글에서는 "저시력자를 위한 실내 근거리 물체 탐지 및 알림 시스템" 프로젝트에 대한 개요를 설명했습니다.https://whitecode2718.tistory.com/158 [인공지능 프로젝트] 저시력자를 위한 실내 근거리
whitecode2718.tistory.com
import os
import json
import glob
from PIL import Image
SUNRGBD_ROOT = 'SUNRGBD'
OUTPUT_DIR = os.path.join(SUNRGBD_ROOT, 'yolo_bbox_output_safe')
CLASSES_FILE = os.path.join(SUNRGBD_ROOT, 'classes.txt')
os.makedirs(OUTPUT_DIR, exist_ok=True)
# -----------------------------
# 1. 클래스 이름 → ID 매핑
# -----------------------------
def build_class_mapping():
class_mapping = {}
with open(CLASSES_FILE, 'r') as f:
for i, line in enumerate(f):
name = line.strip()
if name:
class_mapping[name] = i
return class_mapping
# -----------------------------
# 2. JSON → YOLO bounding box 변환 (안전하게)
# -----------------------------
def convert_json_to_yolo_safe(json_files, class_mapping):
for idx_file in json_files:
print(f"처리 중: {os.path.basename(idx_file)}")
try:
with open(idx_file, 'r') as f:
data = json.load(f)
except Exception as e:
print(f"JSON 읽기 오류: {e}")
continue
# object id → 클래스 이름
file_object_map = {}
top_level_objects = data.get("objects", [])
for i, obj in enumerate(top_level_objects):
name = obj.get("name") if isinstance(obj, dict) else obj
if name and name.strip():
file_object_map[i] = name.strip()
# 이미지 크기 확인
img_dir = os.path.dirname(os.path.dirname(idx_file))
img_files = glob.glob(os.path.join(img_dir, 'image', '*.jpg'))
if not img_files:
print(f"이미지 없음: {img_dir}")
continue
img_path = img_files[0]
try:
with Image.open(img_path) as img:
img_width, img_height = img.size
except Exception as e:
print(f"이미지 열기 오류: {e}")
continue
# TXT 파일 경로
base_name = os.path.splitext(os.path.basename(img_path))[0]
txt_path = os.path.join(OUTPUT_DIR, f"{base_name}.txt")
yolo_lines = []
frames = data.get("frames", [])
for frame in frames:
polygons_to_process = frame.get("polygon", [frame])
for p in polygons_to_process:
obj_id = p.get("object")
class_name = file_object_map.get(obj_id)
if class_name is None:
continue
x_list = p.get("x", [])
y_list = p.get("y", [])
if not x_list or not y_list or len(x_list) != len(y_list):
continue
# 바운딩 박스 계산
x_min = min(x_list)
x_max = max(x_list)
y_min = min(y_list)
y_max = max(y_list)
# YOLO 정규화 & 안전 클리핑
x_center = (x_min + x_max) / 2.0 / img_width
y_center = (y_min + y_max) / 2.0 / img_height
width = (x_max - x_min) / img_width
height = (y_max - y_min) / img_height
# 0~1 범위로 클리핑
x_center = min(max(x_center, 0.0), 1.0)
y_center = min(max(y_center, 0.0), 1.0)
width = min(max(width, 0.0), 1.0)
height = min(max(height, 0.0), 1.0)
# width, height가 0이면 제거
if width == 0 or height == 0:
continue
class_id = class_mapping.get(class_name, -1)
if class_id == -1:
continue
line = f"{class_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}"
yolo_lines.append(line)
# 저장
if yolo_lines:
with open(txt_path, 'w') as f_out:
f_out.write("\n".join(yolo_lines) + "\n")
print(f"저장 완료: {txt_path} ({len(yolo_lines)}개 바운딩 박스)")
# -----------------------------
# 메인 실행
# -----------------------------
class_mapping = build_class_mapping()
search_pattern = os.path.join(SUNRGBD_ROOT, '*', 'NYUdata', '**', 'annotation', 'index.json')
json_files = glob.glob(search_pattern, recursive=True)
print(f"총 {len(json_files)}개의 JSON 파일 변환 시작")
convert_json_to_yolo_safe(json_files, class_mapping)
print("✅ 안전한 YOLO 바운딩 박스 변환 완료")
클래스도 당연히 이전과 동일하고 json파일에 대한 예외처리를 해두었습니다.
2단계. 모델 재학습
이 부분 역시 이전에 사용했던 yolo_seg(인공지능).ipynb를 그대로 코랩에서 실행하면 되는데, Detect 모델로 교체만 합니다.
# ⚙️ 모델 로드 및 학습
model = YOLO('yolo11n.pt') # 이 부분만 변경하면 됩니다.
model.train(
data=yaml_path,
epochs=100,
imgsz=512,
batch=32,
)
Detect 모델 결과 해석

mAP는 0.271로 이전과 비교했을 때, 조금 향상하였습니다.

역시나 검증셋의 에포크당 손실함수 값을 보면 이전과 비슷한 위치에서 오버피팅이 발생하였고, mAP도 특정 값으로 수렴하고 있음을 확인할 수 있습니다.

여기서 데이터셋에 대한 여러 기법을 적용해 성능을 조금이라도 올릴수 있지만, 프로젝트 목적에 맞게 다른 데이터셋을 구축하는게 더 좋다고 판단했습니다.
3. 데이터셋 교체
1단계. Roboflow에서 데이터셋 구축하기
Yolo 모델을 학습시키기 위한 데이터셋은 다른 플랫폼을 이용하지 않아도 image- label의 짝을 만든 후 train/test/val 로 구성하면 됩니다. label에 들어갈 값은 클래스 정보와 바운딩 박스의 위치 정보이고, 바운딩 박스 정보를 픽셀의 위치에 매핑해 직접 만들수 있습니다. 이 부분은 나중에 OpenCV를 활용하여 프로그램으로 만들어 보겠습니다.
위의 과정을 직접하는건 번거롭고 시간이 상당히 많이 걸리기 때문에, 라벨링과 모델 학습을 자동화시켜주는 roboflow라는 사이트를 이용했습니다. roboflow는 데이터셋을 만드는 유용한 플랫폼이며 yolo의 detect, seg 뿐만 아니라 다양한 기능을 제공합니다.
Roboflow: Computer vision tools for developers and enterprises
Everything you need to build and deploy computer vision models, from automated annotation tools to high-performance deployment solutions.
roboflow.com
무료버전은 3개의 크레딧으로 모델을 학습시킬수 있습니다. 저는 데이터셋만 만들고 모델 학습은 구글 코랩에서 따로 진행하기 때문에 별도의 크레딧 소모없이 데이터셋을 만들 수 있습니다.
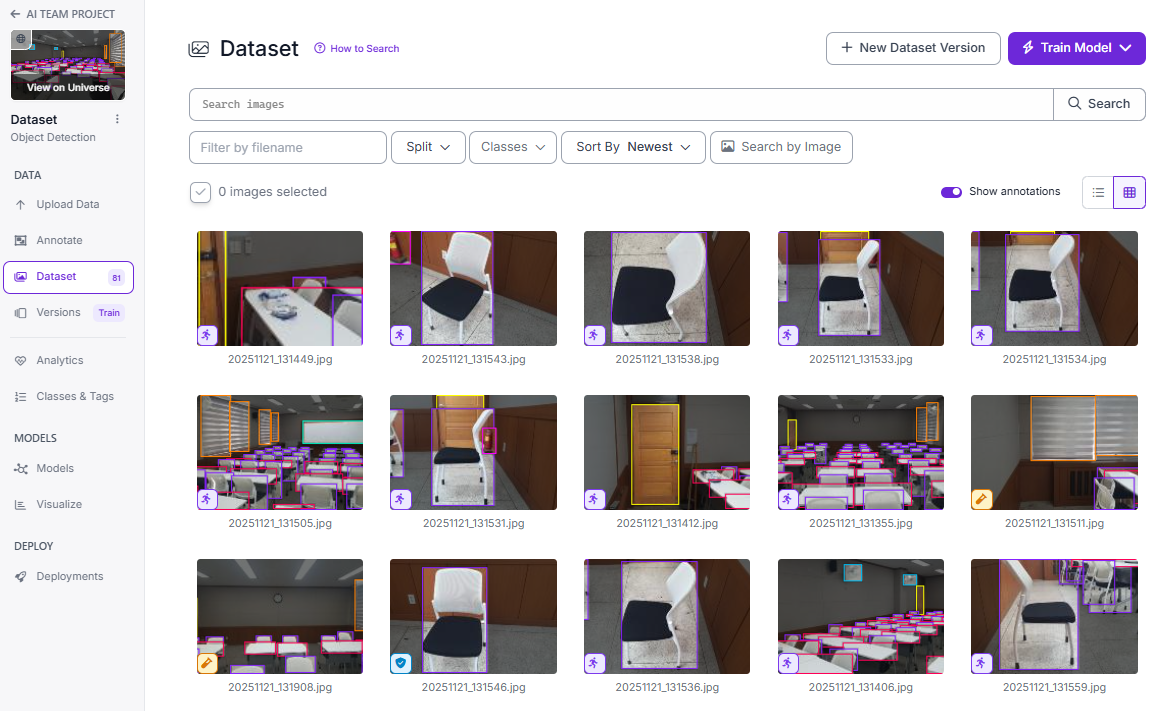
Upload Data 탭에 이미지를 올리고 Annotate 작업을 하면 됩니다. 저희 팀은 프로젝트 시연을 위해 Chair, Curtain, Desk, Door, Fan, Fire extinguisher, Whiteboard를 라벨링 하였습니다.
시간상의 문제로 데이터를 많이 수집할순 없어서 3배수의 데이터증강 기법이 적용된 Train set(171장), Valid set(14장), Test set(10장)으로 데이터를 구성하였습니다.

데이터셋을 다 만들었다면 versions 탭에서 Download Dataset를 누르고 데이터셋 관련 코드를 받아오면 됩니다. 자세한 방법은 따로 다루겠습니다.
2단계. 재학습 및 결과 해석
# ⚙️ 모델 로드 및 학습
from ultralytics import YOLO
model = YOLO('yolo11x.pt') # pretrained model
# 학습
model.train(
data='/content/Dataset-2/data.yaml',
epochs=300,
imgsz=512,
batch=16,
)
Roboflow 플랫폼에서 데이터셋을 받으면 yaml 파일까지 알아서 다운로드 됩니다. yaml 파일내에 train, test, val 위치만 잘 설정해 주면 됩니다.
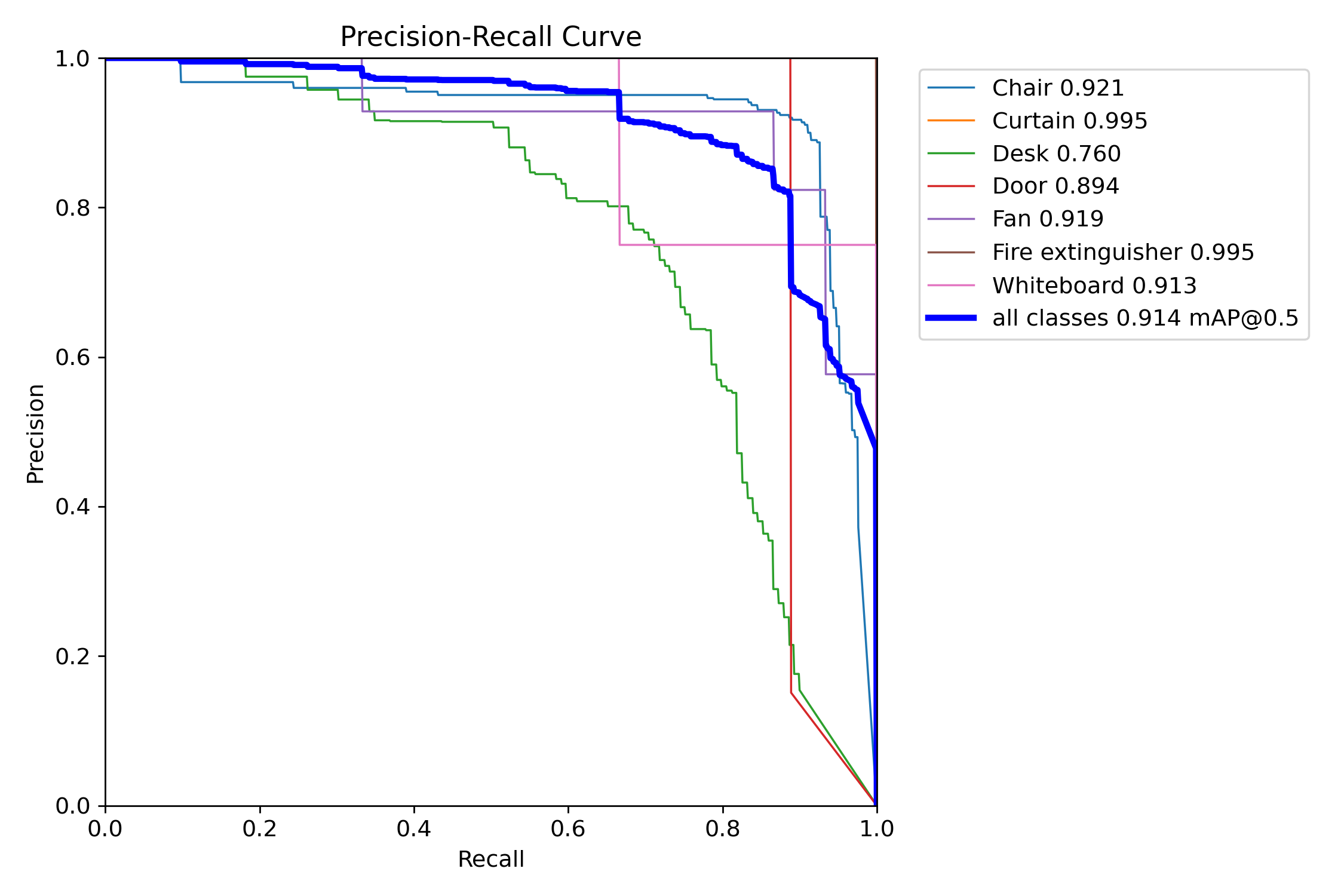
mAP는 0.914로 상당히 높은 수준으로 보입니다.
데이터수가 적을 경우 confusion_martix를 보면 어떤 객체를 잘 검출했는지, 잘못 검출 했는지 알 수 있습니다.
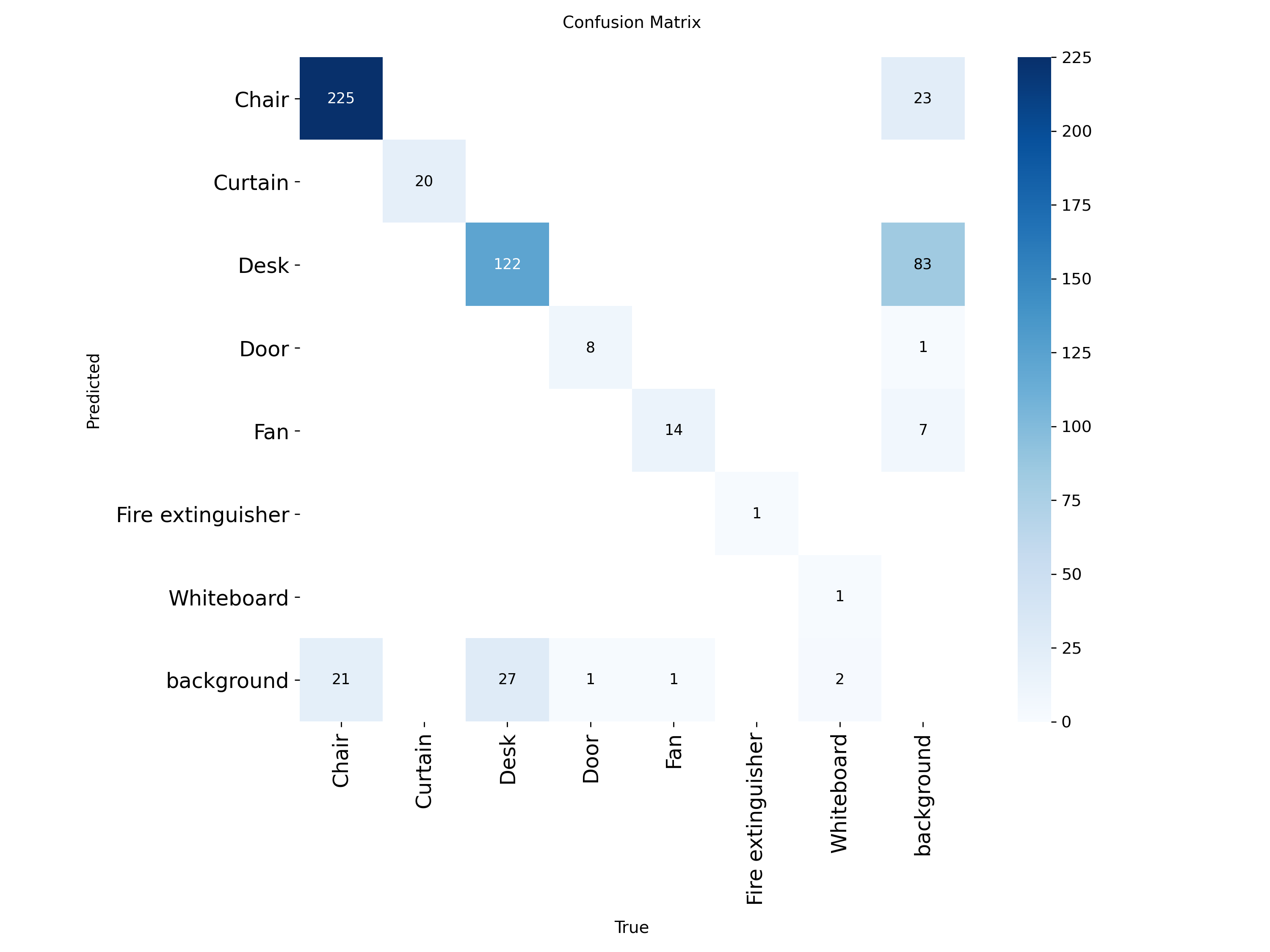
confusion matrix 를 보면 door, fan, fireextinguisher, whiteboard의 객체수가 매우 적고, 배경을 Desk라고 잘못 검출하게 되는 경우가 많았음을 알 수 있습니다.
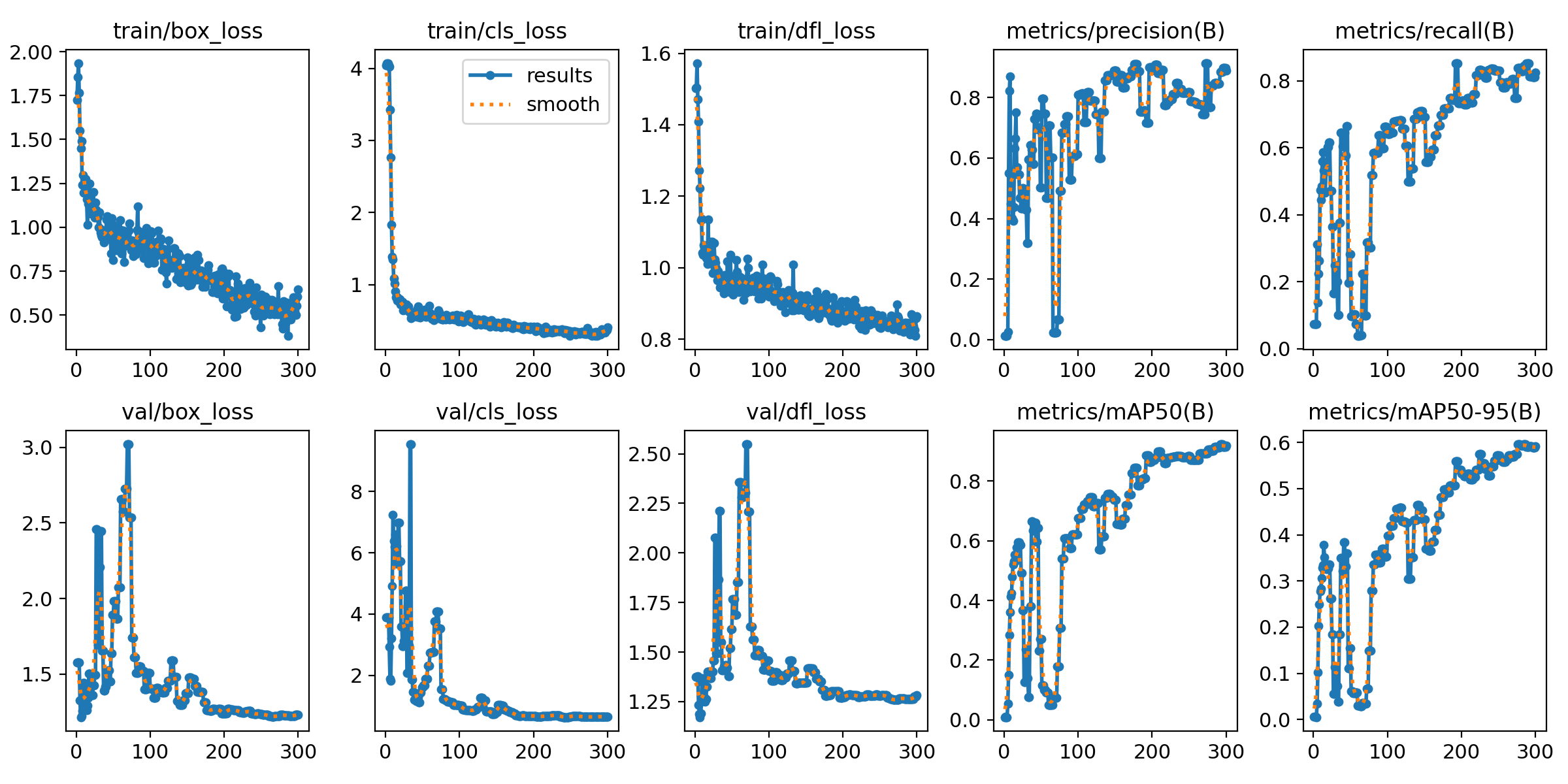
중간에 검증셋의 손실함수가 갑자기 커졌다가 줄어든 경향을 보입니다. 이는 100 에포크 전까지는 학습이 불안정 했음을 의미합니다. 하지만 그 이후 지속적으로 감소하는 경향을 봐서 학습은 정상적으로 진행했습니다. 이경우 오버피팅은 발생하지 않았습니다. mAP도 어느값으로 수렴하지 않고 계속 증가하게 됩니다.

test 이미지가 10장에 mAP가 0.915라는 건, 충분한 정확도를 가진다기 보다는 데이터수가 매우 적기 때문에 잠시 모델의 성능이 좋아 보이는 현상이라고 생각할수 있습니다. 실제로 배경을 Desk라고 인식하는 경우가 많았습니다.
정리하면 다음과 같습니다.
- mAP 결과
- mAP는 0.914로 수치상 높은 성능을 보임
- Confusion Matrix의 역할
- 데이터 수가 적은 경우, 객체별 검출 성능과 오검출 양상을 파악하는 데 유용함
- Confusion Matrix 분석 결과
- door, fan, fireextinguisher, whiteboard 클래스는 샘플 수가 매우 적음
- 배경을 Desk 클래스로 잘못 검출하는 경우가 빈번하게 발생함
- 학습 과정 분석 (results.png)
- 검증 손실이 중간에 급증 후 감소하는 경향을 보임
- 100 epoch 이전까지 학습이 불안정했으나 이후 안정적으로 수렴함
- 오버피팅은 발생하지 않았으며, mAP는 지속적으로 증가함
- 테스트 결과 해석 (val_batch0_pred.png)
- 테스트 이미지 10장 기준 mAP 0.915는 데이터 수가 적어 과대평가되었을 가능성이 큼
- 실제 예측에서는 배경을 Desk로 인식하는 오류가 다수 확인됨
4. 결론
결과적으로, 프로젝트의 "검출"기능은 mAP 기준으로 0.1 에서 0.9로 크게 향상시켰습니다. 다만, 아직 데이터의 수가 적고 오분류 정도가 크기 때문에 개선의 여지가 많이 남아 있습니다.
추후 프로젝트에서는 두 모델 모두 사용해 프로토 타입의 성능을 비교할 예정입니다.