
이전 글에서는 "저시력자를 위한 실내 근거리 물체 탐지 및 알림 시스템" 프로젝트에서 YOLOv11n 검출 모델을 어떻게 학습시키는 지와 결과 해석에 대해서 다루었습니다.
[인공지능 프로젝트] 저시력자를 위한 실내 근거리 물체 탐지 및 알림 시스템 - 3편 (YOLOv11n-seg 모
이전 글에서는 "저시력자를 위한 실내 근거리 물체 탐지 및 알림 시스템" 프로젝트에서 YOLO 모델 재학습을 위한 데이터 전처리 과정 설명했습니다. https://whitecode2718.tistory.com/160 [인공지능 프로젝
whitecode2718.tistory.com
본 글에서는 프로젝트에서 진행한 단안 깊이 추정 모델의 학습 과정과 결과 해석에 대해 구체적으로 소개하겠습니다.
📌 깃허브 링크: https://github.com/lko9911/Artificial-Intelligence-Project
GitHub - lko9911/Artificial-Intelligence-Project: 강원대학교 인공지능 수업_프로젝트
강원대학교 인공지능 수업_프로젝트. Contribute to lko9911/Artificial-Intelligence-Project development by creating an account on GitHub.
github.com
📌 Depth 추정 모델 학습 코드: https://github.com/lko9911/Artificial-Intelligence-Project/blob/main/Prototype/Depth/Learing_model2.py
Artificial-Intelligence-Project/Prototype/Depth/Learing_model2.py at main · lko9911/Artificial-Intelligence-Project
강원대학교 인공지능 수업_프로젝트. Contribute to lko9911/Artificial-Intelligence-Project development by creating an account on GitHub.
github.com
1. 단안 깊이 추정 모델이란?
단안 깊이 추정(Monocular Depth Estimation)이란?
단안 깊이 추정 모델은 단 하나의 RGB 이미지를 입력으로 받아 각 픽셀마다 카메라로부터의 거리(깊이, Depth) 를 예측하는 딥러닝 모델입니다.
기존의 깊이 측정 방식은 스테레오 카메라, LiDAR, ToF 센서와 같이 추가적인 하드웨어를 필요로 합니다. 반면 단안 깊이 추정은 카메라 한 대만으로도 깊이 정보를 추정할 수 있다는 장점이 있습니다.
단일 이미지로 깊이를 추정하는 원리
단안 깊이 추정 모델은 대규모 데이터셋을 통해 다음과 같은 시각적 단서를 학습합니다.
- 객체의 상대적 크기
- 원근법(perspective)
- 텍스처 밀도 변화
- 명암과 그림자
- 장면의 구조적 정보(도로, 건물, 하늘 등)
이러한 정보를 기반으로 모델은 픽셀 단위의 깊이 맵(depth map) 을 출력합니다.
활용 분야
- 자율주행 차량의 거리 인식
- 로봇 내비게이션 및 경로 계획
- AR/VR 환경에서의 공간 인식
- 단일 이미지 기반 3D 재구성
- 스마트폰 카메라의 인물 모드 및 배경 분리
평가 지표
단안 깊이 추정은 분류 문제가 아닌 회귀(regression) 문제이므로, 오차 기반 평가 지표를 사용합니다.
Absolute Relative Error (Abs Rel)
실제 깊이에 대한 상대적 오차를 나타내는 지표입니다.
값이 작을수록 성능이 우수합니다.
Squared Relative Error (Sq Rel)
오차를 제곱하여 계산하는 지표로, 큰 오차에 더 민감합니다.
특히 먼 거리 객체의 예측 성능 평가에 사용됩니다.
RMSE (Root Mean Squared Error)
전체 예측 오차의 평균적인 크기를 나타냅니다.
이상치(outlier)에 민감한 특성이 있습니다.
RMSE (log)
깊이를 로그 스케일로 변환하여 계산한 RMSE입니다.
가까운 거리와 먼 거리 모두를 균형 있게 평가할 수 있습니다.
Accuracy (δ < threshold)
예측 깊이가 실제 깊이 대비 일정 비율 이내에 들어오는 픽셀의 비율을 의미합니다.
일반적으로 δ < 1.25, 1.25², 1.25³ 기준을 사용하며, 값이 클수록 성능이 우수합니다.
저의 팀은 Abs Rel, RMSE(log), δ < 1.25 를 사용해 성능을 평가하였습니다.
DeepLabV3란?
DeepLabV3는 Google에서 제안한 Semantic Segmentation(의미 분할) 모델입니다. 입력 이미지를 픽셀 단위로 분류하여 도로, 보도, 차량, 사람 등의 의미적 클래스를 구분합니다. 본 연구에서는 DeepLabV3 구조를 기반으로 모델을 재구성하여 단안 깊이맵 추정을 수행하였습니다.
구조적 특징
DeepLabV3는 Encoder 중심 구조를 기반으로 합니다. Encoder에서는 Atrous Convolution과 Atrous Spatial Pyramid Pooling(ASPP) 구조를 사용하여 다양한 스케일의 문맥 정보를 효과적으로 추출합니다. DeepLabV3는 별도의 Decoder 구조를 포함하지 않으며, 이로 인해 고해상도 경계 복원보다는 전역적인 문맥 정보 표현에 강점을 가집니다.
단안 깊이 추정과의 관계
DeepLabV3는 본래 의미 분할을 목적으로 설계된 모델로, 깊이 값을 직접 예측하도록 설계되지는 않았습니다. 그러나 본 연구에서는 파인튜닝을 수행함으로써, 픽셀 단위의 깊이맵을 추정하는 단안 깊이 추정 모델로 활용하였습니다. 이를 통해 DeepLabV3가 갖는 다중 스케일 문맥 정보 추출 능력을 단안 깊이 추정 문제에 효과적으로 적용할 수 있었습니다.
2. DeepLabV3 사용 이유

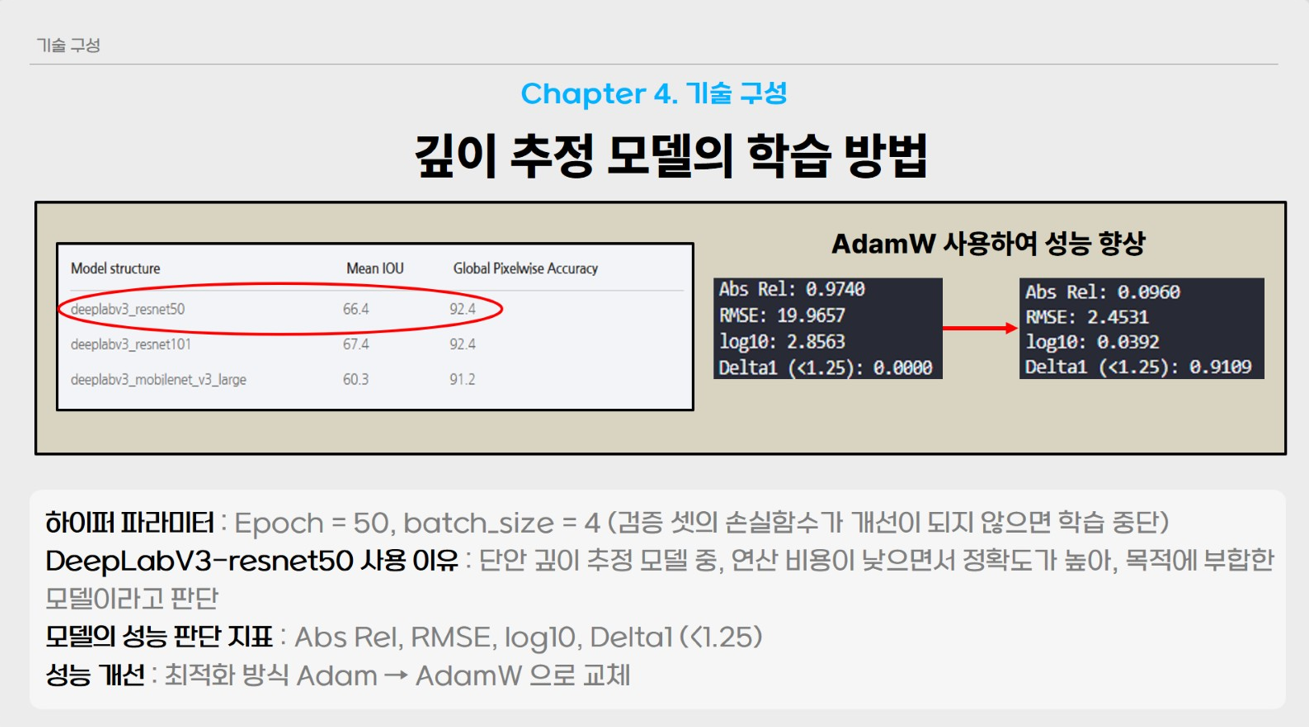
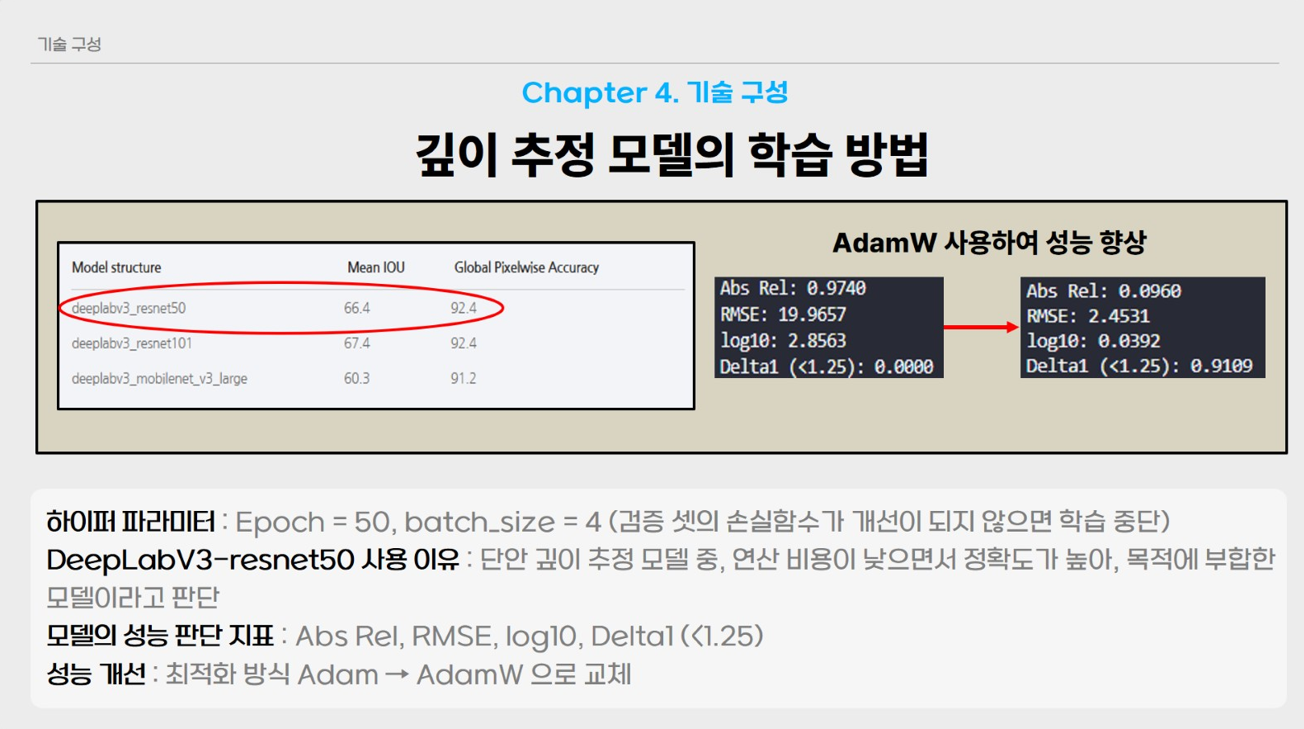
저희 팀은 Torchvision의 객체를 분할하여 검출하고, 깊이 추정이 가능한 DeepLabV3 (Resnet50 Backbone) 모델을 파인튜닝하여 사용하였습니다. 깊이 추정 모델이 정말 다양하지만, 그중 DeepLabV3을 선택한 이유는 다음과 같습니다.
- 깊이 추정 모델중 가장 간단하게 사용할 수 있다.
- 간단하게 사용할 수 있는 모델 중 연산량이 적으면서 성능이 좋은 모델
물론 모델을 선택하는 가장 좋은 방식은 여러 깊이 추정 모델을 같은 데이터셋으로 파인튜닝하여 각각의 성능을 비교해 가장 성능이 좋았던 모델을 선택하는 것이지만, 프로젝트의 수행시간을 고려하여 DeeplabV3 (Resnet50 Backbone)을 사용하였습니다.
3. 데이터 전처리
이전에 YOLO 모델을 학습시켰듯이 DeeplabV3 모델을 학습시키기 위한 데이터셋을 별도로 구성해야 합니다.
Dataset_NYU
ㄴimages
ㄴNYU0001.jpg
ㄴNYU0002.jpg...
ㄴDepth
ㄴNYU0001.jpg
ㄴNYU0002.jpg...
YOLO 와는 다르게 라벨 데이터로 사용하는 Depth는 이미지형태로 되어있습니다. 대체로 Depth의 라벨 데이터는 각 픽셀에 거리 정보를 담아 표현하는 Depth Map으로 되어있습니다. 이 부분은 다음에 자세히 소개하겠습니다.

depth 폴더안에 라벨데이터(이미지) 가 들어있기 때문에 따로 코드를 사용하여 데이터 셋을 만들었습니다.
4. 모델 학습 과정
구글드라이브에 데이터셋을 업로드하고 코랩에서 모델을 학습시켜도 됐지만, 로컬로 진행해도 문제없다는 생각에 VS code로 모델을 파인튜닝하였습니다.
import os
import cv2
import random
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchvision.models.segmentation import deeplabv3_resnet50
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm
from PIL import Image
# ==========================
# Config 설정
# ==========================
class Config:
root_dir = "Depth/Dataset"
checkpoint_dir = "./checkpoints_depth"
batch_size = 4
learning_rate = 1e-4
num_workers = 4
epochs = 44
device = "cuda" if torch.cuda.is_available() else "cpu"
train_ratio = 0.8
val_ratio = 0.1
test_ratio = 0.1
seed = 42
# ==========================
# 재현성 보장
# ==========================
def seed_everything(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# ==========================
# DepthDataset
# ==========================
class DepthDataset(Dataset):
def __init__(self, root_dir, indices=None):
self.image_dir = os.path.join(root_dir, "images")
self.depth_dir = os.path.join(root_dir, "depth")
self.image_files = sorted(os.listdir(self.image_dir))
self.depth_files = sorted(os.listdir(self.depth_dir))
if indices is not None:
self.image_files = [self.image_files[i] for i in indices]
self.depth_files = [self.depth_files[i] for i in indices]
self.img_size = (512, 256) # width, height
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_path = os.path.join(self.image_dir, self.image_files[idx])
depth_path = os.path.join(self.depth_dir, self.depth_files[idx])
image = Image.open(img_path).convert("RGB").resize(self.img_size)
image = transforms.ToTensor()(image)
depth = cv2.imread(depth_path, cv2.IMREAD_UNCHANGED).astype("float32") / 1000.0
depth[depth <= 0] = 0.01
depth = cv2.resize(depth, self.img_size)
depth = torch.from_numpy(depth).unsqueeze(0)
return image, depth
# ==========================
# 모델 정의
# ==========================
class DeepLabv3Plus_Depth(nn.Module):
def __init__(self, output_channels=1):
super().__init__()
self.model = deeplabv3_resnet50(weights=None)
self.model.classifier[-1] = nn.Sequential(
nn.Conv2d(256, output_channels, kernel_size=1),
nn.Softplus() # 더 안정적인 양수 출력
)
def forward(self, x):
out = self.model(x)["out"]
return torch.nn.functional.interpolate(out, size=x.shape[2:], mode="bilinear", align_corners=False)
# ==========================
# Scale-Invariant Loss
# ==========================
def scale_invariant_loss(pred, target):
if pred.shape != target.shape:
target = torch.nn.functional.interpolate(target, size=pred.shape[2:], mode='nearest')
valid_mask = (target > 0)
pred = pred[valid_mask]
target = target[valid_mask]
if pred.numel() == 0:
return torch.tensor(0.0, device=pred.device)
pred = torch.clamp(pred, min=1e-3)
target = torch.clamp(target, min=1e-3)
diff = torch.log(pred) - torch.log(target)
loss = torch.mean(diff ** 2) - (torch.mean(diff) ** 2)
return loss
# ==========================
# Train / Validation
# ==========================
def train_one_epoch(model, loader, optimizer, criterion, device):
model.train()
total_loss = 0
pbar = tqdm(loader, desc="Training", ncols=100)
for imgs, depths in pbar:
imgs, depths = imgs.to(device), depths.to(device)
preds = model(imgs)
loss = criterion(preds, depths)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
pbar.set_postfix(loss=loss.item())
return total_loss / len(loader)
def validate(model, loader, criterion, device):
model.eval()
total_loss = 0
with torch.no_grad():
for imgs, depths in tqdm(loader, desc="Validation", ncols=100):
imgs, depths = imgs.to(device), depths.to(device)
preds = model(imgs)
loss = criterion(preds, depths)
total_loss += loss.item()
return total_loss / len(loader)
# ==========================
# Checkpoint 함수
# ==========================
def save_checkpoint(model, optimizer, epoch, val_loss, path):
torch.save({
"epoch": epoch,
"model_state": model.state_dict(),
"optimizer_state": optimizer.state_dict() if optimizer else None,
"val_loss": val_loss
}, path)
def load_checkpoint(model, optimizer, path, device):
checkpoint = torch.load(path, map_location=device)
model.load_state_dict(checkpoint["model_state"])
if optimizer and checkpoint.get("optimizer_state"):
optimizer.load_state_dict(checkpoint["optimizer_state"])
return checkpoint["epoch"], checkpoint["val_loss"]
# ==========================
# Dataset Split
# ==========================
def split_dataset(dataset, cfg):
total_size = len(dataset)
train_size = int(total_size * cfg.train_ratio)
val_size = int(total_size * cfg.val_ratio)
test_size = total_size - train_size - val_size
indices = list(range(total_size))
random.seed(cfg.seed)
random.shuffle(indices)
train_idx = indices[:train_size]
val_idx = indices[train_size:train_size + val_size]
test_idx = indices[train_size + val_size:]
return train_idx, val_idx, test_idx
# ==========================
# Visualization
# ==========================
def visualize_predictions(model, dataset, device, num_samples=5, save_dir="./results_depth"):
os.makedirs(save_dir, exist_ok=True)
model.eval()
indices = random.sample(range(len(dataset)), num_samples)
with torch.no_grad():
for i in indices:
image, depth_gt = dataset[i]
image_batch = image.unsqueeze(0).to(device)
pred = model(image_batch).squeeze().cpu().numpy()
# 시각화용 정규화
pred_vis = (pred - np.min(pred)) / (np.max(pred) - np.min(pred) + 1e-6)
gt_vis = depth_gt.squeeze().numpy()
gt_vis = (gt_vis - np.min(gt_vis)) / (np.max(gt_vis) - np.min(gt_vis) + 1e-6)
image_np = image.permute(1, 2, 0).numpy()
fig, axs = plt.subplots(1, 3, figsize=(12, 4))
axs[0].imshow(image_np)
axs[0].set_title("Input Image")
axs[1].imshow(gt_vis, cmap='plasma')
axs[1].set_title("Ground Truth")
axs[2].imshow(pred_vis, cmap='plasma')
axs[2].set_title("Predicted Depth")
for ax in axs:
ax.axis('off')
plt.tight_layout()
save_path = os.path.join(save_dir, f"sample_{i}.png")
plt.savefig(save_path)
plt.close()
print(f"[Saved] {save_path}")
# ==========================
# Main
# ==========================
if __name__ == "__main__":
cfg = Config()
seed_everything(cfg.seed)
device = cfg.device
os.makedirs(cfg.checkpoint_dir, exist_ok=True)
print(f"✅ Using device: {device}")
full_dataset = DepthDataset(cfg.root_dir)
train_idx, val_idx, test_idx = split_dataset(full_dataset, cfg)
train_loader = DataLoader(DepthDataset(cfg.root_dir, train_idx), batch_size=cfg.batch_size, shuffle=True, num_workers=cfg.num_workers, pin_memory=True)
val_loader = DataLoader(DepthDataset(cfg.root_dir, val_idx), batch_size=cfg.batch_size, shuffle=False, num_workers=cfg.num_workers, pin_memory=True)
test_loader = DataLoader(DepthDataset(cfg.root_dir, test_idx), batch_size=1, shuffle=False)
model = DeepLabv3Plus_Depth().to(device)
criterion = scale_invariant_loss
optimizer = optim.Adam(model.parameters(), lr=cfg.learning_rate)
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=3)
best_val_loss = float("inf")
start_epoch = 0
resume = True
last_ckpt = os.path.join(cfg.checkpoint_dir, "last.pth")
# Resume 기능
if resume and os.path.exists(last_ckpt):
start_epoch, best_val_loss = load_checkpoint(model, optimizer, last_ckpt, device)
start_epoch += 1
print(f"[INFO] Resumed from epoch {start_epoch}, best loss {best_val_loss:.4f}")
log_path = os.path.join(cfg.checkpoint_dir, "train_log.txt")
with open(log_path, "w") as f:
f.write("epoch,train_loss,val_loss,lr\n")
patience, no_improve = 5, 0
for epoch in range(start_epoch, cfg.epochs):
print(f"\n📘 Epoch {epoch+1}/{cfg.epochs}")
train_loss = train_one_epoch(model, train_loader, optimizer, criterion, device)
val_loss = validate(model, val_loader, criterion, device)
scheduler.step(val_loss)
lr = optimizer.param_groups[0]['lr']
print(f"[Epoch {epoch+1}] Train: {train_loss:.4f} | Val: {val_loss:.4f} | LR: {lr:.6f}")
with open(log_path, "a") as f:
f.write(f"{epoch+1},{train_loss:.6f},{val_loss:.6f},{lr:.8f}\n")
save_checkpoint(model, optimizer, epoch, val_loss, last_ckpt)
if val_loss < best_val_loss:
best_val_loss = val_loss
save_checkpoint(model, None, epoch, val_loss, os.path.join(cfg.checkpoint_dir, "best.pth"))
print(f"💾 Best model updated ({best_val_loss:.4f})")
no_improve = 0
else:
no_improve += 1
if no_improve >= patience:
print("⏹ Early stopping triggered!")
break
# Test phase
print("\n🔍 Testing best model...")
best_ckpt = os.path.join(cfg.checkpoint_dir, "best.pth")
load_checkpoint(model, None, best_ckpt, device)
test_loss = validate(model, test_loader, criterion, device)
print(f"\n✅ Test loss: {test_loss:.4f}")
# === 추가 ===
visualize_predictions(model, train_dataset, device, num_samples=5, save_dir="./results_depth_train")
visualize_predictions(model, val_dataset, device, num_samples=5, save_dir="./results_depth_val")
visualize_predictions(model, test_dataset, device, num_samples=5, save_dir="./results_depth_test")
코드의 흐름은 주어진 데이터셋을 train/test/valid로 분리한 다음, 기존 모델을 불러와 파인튜닝하였습니다. 하이퍼파라미터는 다음과 같습니다.
⚡️ 데이터셋 및 입력 설정
- 입력 이미지 크기:
- 512×256512 \times 256 (width × height)
- 입력 채널 수:
- RGB 3채널
- 깊이맵 전처리
- 원본 깊이값을 1000으로 나누어 미터 단위로 정규화함
- 깊이값이 0 이하인 픽셀은 0.01로 치환하여 로그 연산 안정성 확보
- 데이터 분할 비율
- 학습(Train): 80%
- 검증(Validation): 10%
- 테스트(Test): 10%
- 랜덤 시드(seed): 42
→ 실험 재현성을 확보함
⚡️ 모델 구조 설정
- 기반 모델:
- DeepLabV3 (ResNet-50 backbone)
- 사전학습 가중치:
- 사용하지 않음 (weights=None)
- 출력 채널 수:
- 1채널 (픽셀 단위 깊이맵 회귀)
- 출력 계층 수정
- 1×11 \times 1 Convolution을 사용하여 깊이값 예측
- 활성화 함수로 Softplus 적용
→ 깊이값이 항상 양수가 되도록 보장
- 출력 해상도
- Bilinear interpolation을 사용하여 입력 이미지 해상도로 업샘플링 수행
⚡️ 손실 함수 (Loss Function)
- 사용한 손실 함수:
- Scale-Invariant Loss
- 특징
- 로그 공간에서 예측 깊이와 실제 깊이 간의 상대적 차이를 계산
- 절대 스케일보다는 깊이 구조의 일관성을 학습하도록 유도
- 유효 깊이값(>0) 픽셀만을 대상으로 손실 계산 수행
- 목적
- 단안 깊이 추정에서 발생하는 스케일 불확실성 문제를 완화함
⚡️ 학습 하이퍼파라미터
- 배치 크기 (Batch Size): 4
- 학습률 (Learning Rate): 1×10−41 \times 10^{-4}
- 최적화 알고리즘:
- Adam Optimizer
- 에폭 수 (Epochs): 최대 44
- 데이터 로더 워커 수: 4
- 디바이스 설정:
- CUDA 사용 가능 시 GPU, 그렇지 않으면 CPU
⚡️ 학습률 스케줄러 설정
- 스케줄러 종류:
- ReduceLROnPlateau
- 모니터링 지표:
- Validation Loss
- 감소 비율 (factor): 0.5
- 대기 에폭 수 (patience): 3
- 의미
- 검증 손실이 개선되지 않을 경우 학습률을 점진적으로 감소시켜 안정적인 수렴을 유도함
⚡️ 학습 전략 및 체크포인트 설정
- Early Stopping
- Validation loss가 5 에폭 동안 개선되지 않을 경우 학습 종료
- 체크포인트 저장
- last.pth: 매 에폭 최신 모델 저장
- best.pth: 검증 손실이 최소일 때의 모델 저장
- Resume 학습
- 기존 체크포인트가 존재할 경우 학습을 이어서 수행함
⚡️ 평가 및 시각화 설정
- 평가 방식
- Test dataset에 대해 Scale-Invariant Loss로 성능 평가 수행
- 시각화
- 입력 이미지 / 실제 깊이맵 / 예측 깊이맵을 나란히 비교
- 깊이값은 시각화를 위해 Min–Max 정규화 적용
- 결과 이미지는 PNG 파일로 저장
5. 결과 해석
결과는 전반적으로 성능이 좋게 나왔습니다.
본 프로젝트에서 깊이 추정 모델의 성능을 향상시키기 위해 손실함수 최적화 기법으로 사용한 활성화 함수 Adam을 AdamW로 교체하였습니다.
전체적으로 성능이 좋아졌음을 알 수 있습니다. 최종적으로 모델의 학습결과는 아래와 같습니다.


결과를 보면 한 이미지에서 깊이맵의 차이가 클수록 테스트 결과가 않좋음을 알 수 있습니다.
6. 결론
본 글에서는 저시력자를 위한 실내 근거리 물체 탐지 및 알림 시스템 프로젝트의 핵심 구성 요소 중 하나인 단안 깊이 추정 모델의 학습 과정과 결과 분석을 상세히 소개하였습니다.
DeepLabV3(ResNet-50 backbone) 구조를 기반으로 모델을 재구성하고, 단안 깊이 추정 문제에 적합하도록 출력 계층과 손실 함수를 수정하여 파인튜닝을 진행하였습니다. 특히 Scale-Invariant Loss를 적용함으로써 단안 깊이 추정에서 필연적으로 발생하는 스케일 불확실성 문제를 완화하고, 절대 거리보다는 장면의 상대적 깊이 구조를 안정적으로 학습할 수 있음을 확인하였습니다.
실험 결과, 대부분의 테스트 이미지에서 입력 장면의 구조를 잘 반영한 깊이맵이 생성되었으며, 특히 객체 간 상대 거리 관계가 명확한 장면에서는 우수한 예측 성능을 보였습니다. 반면, 한 이미지 내에서 깊이 변화가 매우 크거나 조명·텍스처 정보가 부족한 경우에는 예측 정확도가 상대적으로 저하되는 경향이 관찰되었습니다. 이는 단안 깊이 추정 모델의 일반적인 한계와도 일치하는 결과입니다.
또한 최적화 기법 측면에서 Adam Optimizer를 AdamW로 변경한 결과, 학습 안정성과 일반화 성능이 전반적으로 향상되는 것을 확인하였습니다. 이를 통해 옵티마이저 선택이 단안 깊이 추정 성능에 미치는 영향 역시 중요함을 알 수 있었습니다.
본 프로젝트에서 학습된 깊이 추정 모델은 단독으로 사용되는 것이 아니라, 앞서 학습한 YOLO 기반 객체 검출 모델과 결합되어 저시력자에게 객체까지의 상대적 거리 정보를 제공하는 핵심 모듈로 활용됩니다. 즉, 본 연구의 의의는 단순한 깊이맵 생성에 그치지 않고, 실제 사용자 중심 응용 시스템에 적용 가능하다는 점에 있습니다.
향후 연구 방향으로는
- 사전학습된 깊이 추정 모델(MiDaS, DPT 등)과의 성능 비교
- 의미 분할 정보와 깊이 추정을 결합한 멀티태스크 학습
- 실내 환경에 특화된 데이터셋 확장 및 정량적 평가 지표(Abs Rel, RMSE, δ) 추가 분석
등을 통해 모델의 신뢰성과 실사용 가능성을 더욱 높일 수 있을 것으로 기대됩니다.
본 글이 단안 깊이 추정 모델을 실제 프로젝트에 적용하고자 하는 분들께 하나의 참고 사례가 되기를 바랍니다.