[데이터 시각화] US Stock Market 2020 to 2024 (피벗, 차트)
US Stock Market 2020 to 2024
US Stock Market Dataset: A Comprehensive View of the US Stock Market from Februa
www.kaggle.com
데이터 라이센스 정보

프로젝트의 목표는 요소별 월별 평균값 데이터를 피벗테이블과 차트로 만들어 데이터를 시각화하는 것입니다. (EDA의 일부)
라이브러리 및 데이터 불러오기
간단하게 데이터를 시각화할 때 쓰는 라이브러리입니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
file_name = 'C:/kaggle/US Stock Market Dataset.csv'
df = pd.read_csv(file_name)


날짜별 각 요소의 차트를 그릴 것이기 때문에 Date를 DateTime의 데이터 형식으로, 나머지 object를 정수나 실수형으로 형변환을 해주어야 합니다. 또한 결측치값이 보이므로 데이터 전처리 작업을 합니다.
데이터 전처리 작업
- 결측치 다루기

비율을 보면 Platinum_Vol를 제외하고 0.1% 미만의 결측치 값을 가집니다. 통계나 기계학습을 한다면 지워도 될 정도라고 판단되지만, 데이터 시각화를 목적으로 하기 때문에 이전값이나 이후 값으로 채워 넣습니다.
df_pre = df.drop(columns=['Platinum_Vol.']).ffill().bfill()
# bfill() : missing value that cannot be solved by fillna()
df_pre = pd.concat([df_pre.iloc[:, :11], df['Platinum_Vol.'].fillna(0), df_pre.iloc[:, 11:]], axis=1)
# Platinum_Vol's missing value = 0
ffill() 이후 bfill()을 사용해 이전값을 채운 후 남은 이후값을 채워 넣습니다. 연속적으로 결측치가 존재할 경우 이전값을 채우는데 한계가 있기 때문에 두 함수를 사용했습니다.
Platinum_Vol는 결측치 값의 비율이 높기 때문에 이전값과 이후값으로 채우면 데이터 시각화를 할 때 의미 없는 패턴을 보이는 차트가 됩니다. 때문에 결측치를 0의 값으로 처리해 줍니다.
하나의 칼럼만 제외시키고 결측치를 다뤘기 때문에 Platinum_Vol는 따로 0으로 채운 후 다시 concat으로 이어 붙입니다.

결측치 값이 완전히 제거되었습니다.
- 형변환
원하는 작업을 위해서는 Date를 DateTime의 데이터 형식으로, 나머지 object를 정수나 실수형으로 형변환해주어야 합니다.
Date의 일부를 보았을 때 날짜를 '-'나 '/'를 혼용해서 사용하기 때문에 통합시키고 형변환을 해주어야 오류가 발생하지 않습니다. 물론 데이터의 일부만 보고 판단하는 것이기 때문에 전체 데이터를 확인해 보고 작업해야 합니다.
df_pre['Date'] = df_pre['Date'].str.replace('/', '-')
df_pre['Date'] = pd.to_datetime(df_pre['Date'], format='%d-%m-%Y')
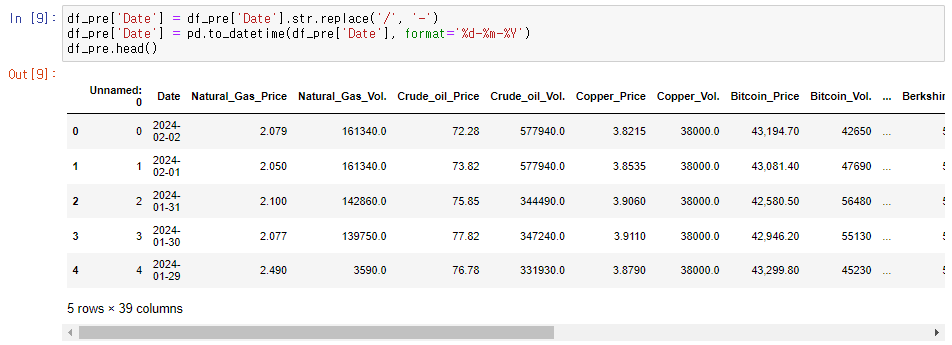
우선 '/' 데이터를 '-'로 대체해 준 후 to_datetime를 사용해 형변환을 진행했습니다. format = '% d-%m-%Y'는 저장되는 데이터 형식입니다.
다음으로 object를 float로 변환하는 과정입니다. 그냥 float의 변환함수만 쓰면 된다고 생각했지만, object 데이터들의 , (콤마)가 문자열이기 때문에 object로 저장된 것이기에 바로 float로 저장하면 값이 왜곡되어 변환됩니다.
때문에 콤마를 제거한 후 숫자형 데이터로 변환해 주어야 데이터의 왜곡을 없앨 수 있습니다.
for col in df_pre.columns:
if df_pre[col].dtype == 'object':
df_pre[col] = df_pre[col].str.replace(',','').astype(float)
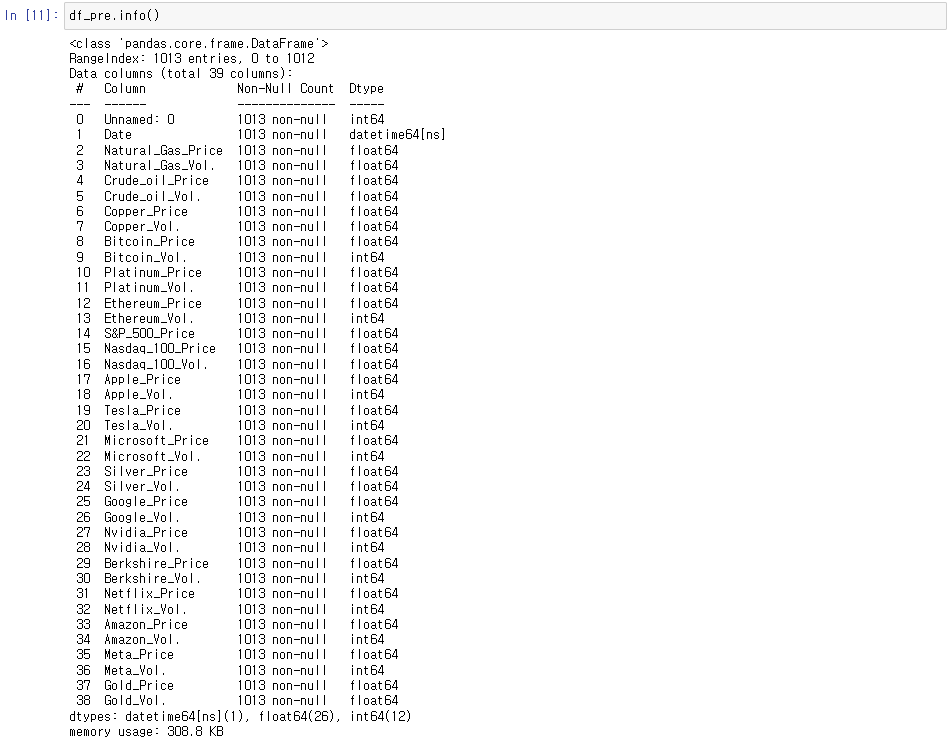
결측치와 데이터 형식의 처리가 마무리되었습니다.
피벗 테이블과 차트
작동 여부와 프로젝트의 목적 달성이 중요하므로 시각화의 자료를 전부 올리지 않고 일부만 게시합니다.
피벗 테이블을 작성하기 위해서는 전처리한 데이터프레임의 날짜와 각 요소를 리스트형태로 분리하고 이 두 리스트로 피벗테이블이나 차트로 만듭니다.
col_price=[]
for col in df_pre.columns.tolist():
if 'Price' in col:
col_price.append(col)
date = df_pre['Date']
'Price'를 가지는 칼럼만 따로 col_price 리스트에 저장합니다.
Date는 아래에 month별로 분리할 겁니다.
- 피벗테이블_ 가격 (평균)
#pivot_table : Price (month_average)
df_pre['Month'] = pd.to_datetime(df_pre['Date']).dt.month
pivot_table_month_1 = pd.pivot_table(df_pre,index='Month', values=col_price, aggfunc='mean')
pivot_table_month_1
Month로 월별 데이터를 별도로 수집해 피벗테이블로 평균값을 계산했습니다.

#pivot_table : Price (month_average) 각 요소별 데이터 표현
for col in col_price:
pivot_table_month_2 = pd.pivot_table(df_pre,index='Month', values=col, aggfunc='mean')
print(pivot_table_month_2)
print('-'*20)

- 차트(막대그래프)_가격 (평균)
# Monthly Average Price Graph
for col in col_price:
pivot_table_month_3 = pd.pivot_table(df_pre,index='Month', values=col, aggfunc='mean')
pivot_table_month_3.plot(kind='bar', color=np.random.rand(3,))
plt.xlabel('Month')
plt.ylabel('Price')
plt.title('Monthly Average Price Graph')
plt.legend()
plt.show()

- 피벗테이블_ 거래량 (평균)
칼럼 분리를 price에서 vol로만 바꾸면 별도의 코드 수정이 필요 없습니다.
col_vol=[]
for col in df_pre.columns.tolist():
if 'Vol' in col:
col_vol.append(col)
#pivot_table : Vol (month_average)
pivot_table_month_4 = pd.pivot_table(df_pre,index='Month', values=col_vol, aggfunc='mean')
pivot_table_month_4

데이터 테이블을 볼 때 주의해야 할 점은 3.0938... 데이터만 보면 작은 값인 것 같지만 뒤에 e+05 같은 과학적 표기법에 유의해야 합니다. 때문에 차트로 시각화하는 게 중요합니다.
#pivot_table : Vol (month_average)
for col in col_vol:
pivot_table_month_5 = pd.pivot_table(df_pre,index='Month', values=col, aggfunc='mean')
print(pivot_table_month_5)
print('-'*20)

- 차트(막대그래프)_평균
# Monthly Average Vol Graph
for col in col_vol:
pivot_table_month_6 = pd.pivot_table(df_pre,index='Month', values=col, aggfunc='mean')
pivot_table_month_6.plot(kind='bar', color=np.random.rand(3,))
plt.xlabel('Month')
plt.ylabel('Vol')
plt.title('Monthly Average Vol Graph')
plt.legend()
plt.show()
정리
이처럼 데이터의 칼럼별 평균을 테이블 형태와 차트 형태로 표현할 수 있습니다. 데이터 시각화의 경우 엑셀 같은 프로그램을 주로 사용하는데 파이썬을 이용해 방대한 자료를 코드 몇 개로 빠르게 시각화할 수 있는 장점을 가집니다.
일별, 연간별의 데이터 자료를 보고 싶으면 아래 깃허브 주소에서 확인해 주세요.
깃허브 : https://github.com/lko9911/Kaggle/blob/master/EDA/EDA-us-stock-market.ipynb
구글 이메일 : lko991111@gmail.com